Amazon S3
Amazon S3(S3)と双方向のデータ連携が可能です。
データ連携のパターン
- 以下の連携が可能です
- Datahubから直接インポートする
- Datahubから直接エクスポートする
AWS側の設定
- ロールを作成します
- ロールの信頼ポリシーにAssume Roleの設定をします
- S3バケットに対してアクセス許可が設定されたポリシーを作成します
- 作成したポリシーをロールの許可ポリシーにアタッチします
- ロールの最大セッション時間を4時間に設定します
詳細はAWSのドキュメントをご覧ください
信頼ポリシーの例
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
// ビルトインGoogleサービスアカウントのクライアントIDを設定します
// クライアントIDは管理画面の [サービスアカウント管理] > [ビルトインGoogleサービスアカウント] > [クライアントID] から確認できます
"accounts.google.com:sub": "CLIENT_ID"
}
}
}
]
}- 連携には次のアクセス許可が必要です。設定が足りない場合はジョブフローが失敗します。
- S3からDatahubへのインポート
s3:GetObjects3:ListBucket
- DatahubからS3へのエクスポート
s3:GetObjects3:PutObjects3:DeleteObjects3:ListBucket
- S3からDatahubへのインポート
詳細はAWSのドキュメントをご覧ください
許可ポリシーの例
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::{YOUR-BUCKET-NAME}",
"arn:aws:s3:::{YOUR-BUCKET-NAME}/*"
]
}
]
}Datahubジョブ設定
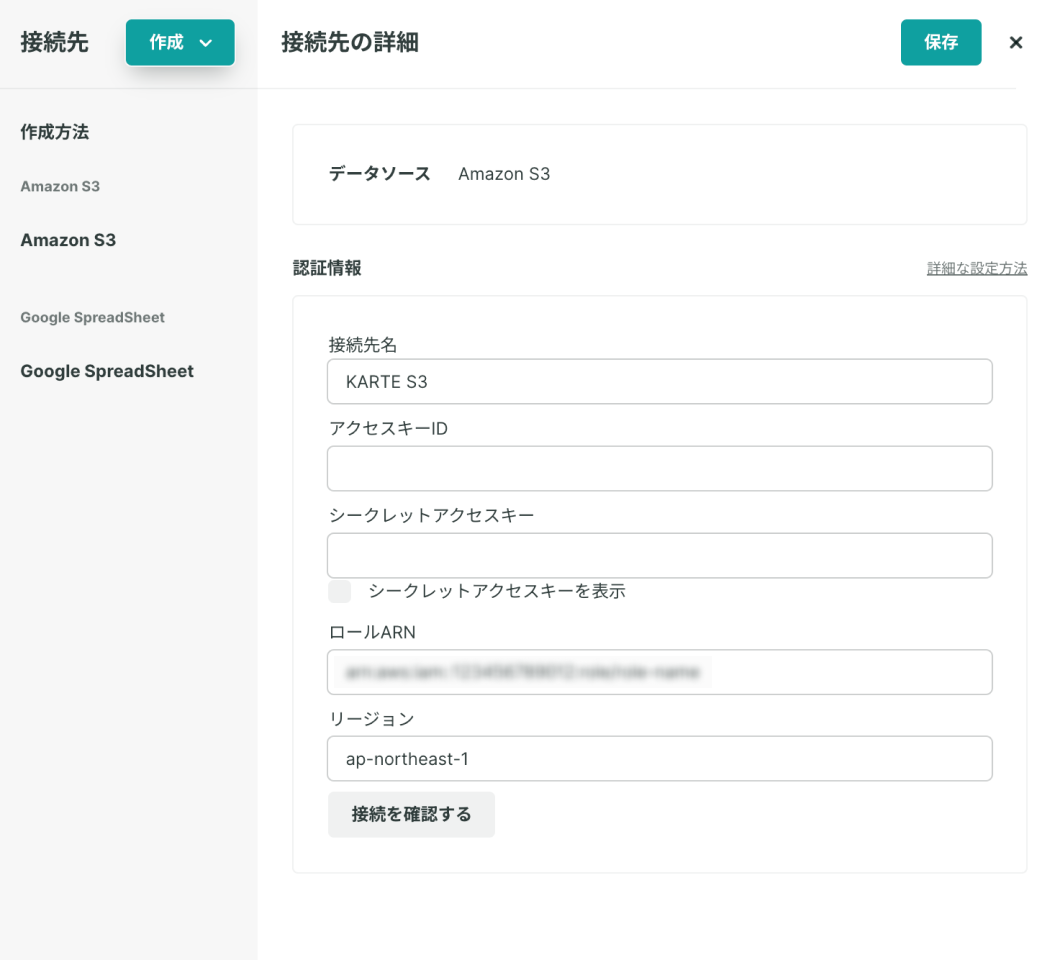
「接続先」
設定が完了したら「接続を確認する」を押下して正しく設定ができているか確認をしてください。 ※ エラーになる場合、設定が正しく出来ていません
- [ロールARN]
- ビルトインGoogleサービスアカウントにアクセスを許可するロールのARNを設定します
- [リージョン]
- バケットのリージョンを設定します
- 詳細はAWSのドキュメントをご覧ください
ロールARNを利用する場合は、アクセスキーID・シークレットアクセスキーは空欄としてください。
KARTEから払い出されるS3バケットのリージョンKARTEのS3バケット払い出し機能によって用意されるS3バケットのリージョンは、ap-northeast-1です。 詳細はこちらをご確認ください
下記のアクセスキーとシークレットアクセスキーによる連携は非推奨になりました
- 連携先S3バケットに対するアクセス権限を保持したIAMユーザーを作成し、アクセスキーとシークレットアクセスキーを取得します 詳細はAWSのドキュメントをご覧ください
Datahubジョブ設定
「接続先」設定が完了したら「接続を確認する」を押下して正しく設定ができているか確認をしてください。 ※ エラーになる場合、設定が正しく出来ていません
- エラーになる場合、設
- 詳細はAWSのドキュメントをご覧ください
- [シークレットアクセスキー]
- 詳細はAWSのドキュメントをご覧ください
- [リージョン]
- 詳細はAWSのドキュメントをご覧ください
個別設定
設定が完了したら「接続を確認する」を押下して正しく設定ができているか確認をしてください。 ※ エラーになる場合、設定が正しく出来ていません
インポート
- [バケット]
- 接続先のS3バケット名を入力します
- 例:
karte-data-bucket
- [ファイルパス]
- 完全一致で指定します
- 例:
foo/bar/baz.csv
- 例:
- gzip圧縮されたファイルもインポート可能です
- ジョブ実行日時を使ったファイルパスの動的指定に対応しています
- 完全一致で指定します
- [プレフィクス]
- 前方一致で指定します
- こちらを入力すると、合致する全てのファイルがインポート対象になります
- 例:
karte-bucketの配下にkarte1.csvkarte2.csvkarte3.csvのファイルがあった場合- プレフィクスを
karteとすると全てのファイルがインポートされます karte1やkarte1.csvではkarte-bucket/karte1.csvのみが対象となります
- プレフィクスを
- ジョブ実行日時を使ったプレフィックスの動的指定に対応しています
- 前方一致で指定します
- 区切り文字
- 入力ファイルの区切り文字を以下から選択します
- カンマ
- タブ
- パイプ
- 入力ファイルの区切り文字を以下から選択します
- フォーマット
- CSV
- Newline Delimited JSON (改行区切りJSON)
- スキーマ
- 「データテーブルのスキーマを指定する」をご覧ください
ファイルパスに使えない文字があります
?,*,[..]などのワイルドカードが含まれている場合、正常に取り込めません。

エクスポート
- バケット
- 例:
karte-bucket
- 例:
- ファイルパス
- 完全一致で指定します
- 例:
foo/bar/baz.csv
- 例:
- ジョブ実行日時を使ったファイルパスの動的指定に対応しています
- 拡張子を省略した場合は、出力形式に応じて自動で設定されます
- 完全一致で指定します
- 出力形式
- 出力ファイルの出力形式を以下から選択します
- CSV
- デフォルト
- JSON (改行区切り)
- CSV
- 出力ファイルの出力形式を以下から選択します
カラム名に使用可能な文字列カラム名には日本語などのマルチバイト文字が使用できません。
英数字と
_(アンダースコア) のみを使用してください。
- オプション
- 後述

オプション
ヘッダー行を出力する
出力されるいずれかのファイルの先頭にヘッダー行を出力します
出力データをダブルクォート(")で囲む
ダブルクォート(")で囲まれたデータを出力します
- 例
- 有効な場合:
"column1","column2" - 無効な場合:
column1,column2
単一ファイルで出力する
オフの場合は後述するようにS3への出力ファイルは分割して出力されます
単一ファイルで出力するオプションが有効でない場合の挙動について例)
EXPORT/karte-datahub.csvを出力した場合EXPORT/karte-datahub-00-of-03.csv EXPORT/karte-datahub-01-of-03.csv EXPORT/karte-datahub-02-of-03.csv各ファイルのサイズとファイルの分割数はシステムによって決定され、実行ごとに異なります。
ヘッダー行を出力するオプションが有効になっている場合は出力される いずれか のファイルの先頭行にヘッダー行が出力されます。
データ型と出力フォーマット出力時に、各データはクォート/ダブルクォート等が付与されない形式で出力されます。 一部の型は下記の形式にフォーマットされ出力されます。
BOOL型:
true/falseDATE型:YYYY-MM-DDTIMESTAMP型:YYYY-MM-DD hh:mm:ss.ffffff UTC
FAQ
Q. 値に改行を含むCSVファイルの取り込みは可能ですか?
- 残念ながら、値に改行を含むCSVファイルについては正しく取り込むことができません
- 対策例
- 改行コードを
\nなどに置換してからCSVファイルに出力する - 代わりにGoogle Cloud Storageを介したデータ連携を利用する
- 改行コードを
Q. インポート対象のファイルが空の場合はジョブエラーになりますか?
- ファイルが0バイトの場合、次のエラーになります
specified s3 file is empty.
- ヘッダー行のみ存在する0件のファイルの場合は、その他の設定が合っていれば正常終了します
- インポートジョブの設定では、スキーマを明示的に指定してください
Q. S3の暗号化オプションを利用していても問題ないですか?
- 以下については、ご利用いただいて問題ありません。
- SSE-S3
- SSE-KMS
- 以下については、現時点では対応していません。
- SSE-C
- CSE
Q. エクスポート時の文字コードと改行コードは?
- エクスポート時の改行コードは以下の通りです
- 文字コード
- UTF-8
- 改行コード
- LF
- 文字コード
Updated 4 months ago